AI zonder vangrails
Met het uitkomen van DeepSeek R1 ging er een schok door de techwereld. De efficiëntie van het model, de lage kosten van het bouwen in het model dat de ontwikkelaars claimden en het feit dat het volledig open source is, zorgden ervoor dat producenten van zowel software als hardware voor artificiële intelligentie (AI) zich zorgen gingen maken over hun toekomst. Al snel leken er echter ook andere zorgen te ontstaan. Uit onderzoek van techbedrijf Cisco, in samenwerking met de University of Pennsylvania, blijkt namelijk dat DeepSeek geen vangrails heeft.

Large Language Models (LLMs) zijn gebouwd op basis van grote hoeveelheden informatie die op het internet te vinden zijn. Wie een vraag stelt aan zo'n model geeft opdracht aan een set algoritmes om op basis van logisch redeneren een antwoord te vinden in deze dataset. En dat loopt niet altijd goed af: sinds Google AI-suggesties bij zoekopdrachten implementeerde, staat het internet vol met bizarre antwoorden. Zo gaf Google bij de vraag hoe men kaas beter op een pizza kan laten plakken de suggestie om lijm in de saus te mengen. Waarschijnlijk komt dit antwoord voort uit een artikel over het fotograferen en filmen van voedsel, waarbij vaak lijm wordt gebruikt om mooie lange kaasdraden te krijgen. Het LLM van Google heeft dit artikel in de database en gebruikte het om een antwoord te genereren, zonder na te denken over de eetbaarheid.
Dat is een voorbeeld van een onbewust schadelijke suggestie van een LLM. Er kan echter ook gevraagd worden naar bewust schadelijke informatie, bijvoorbeeld advies voor het plegen van een misdaad. Ontwikkelaars proberen natuurlijk zo veel mogelijk te voorkomen dat hun modellen voor kwaadaardige doeleinden gebruikt worden. Ook wie zelf geen AI gebruikt kan deze vangrails in het wild tegenkomen, bijvoorbeeld in een social media post die begint met 'As an AI language model, I cannot...' ('Als AI-taalmodel kan ik niet...'). Deze posts worden gemaakt door bots gedreven door AI, die bij de poging tot interactie tegen de grenzen van wat de ontwikkelaars hun modellen willen laten doen aanlopen.
En dat is belangrijk, voor zowel de algemene veiligheid als voor de veiligheid in bedrijfsvoering van organisaties die AI willen gebruiken. Niemand wil dat de nieuwe AI-klantenservice chatbot gevoelige gegevens deelt met klanten, of klanten onwenselijke contracten laat sluiten. Een bekend voorbeeld hiervan is een autoshowroom in Amerika die ChatGPT gebruikte voor klantenservice. Al snel had iemand de chatbot overtuigd om voor één dollar een gloednieuwe auto te verkopen.
Testen
Maar er zijn ook meer algemeen schadelijke manieren waarop LLMs en andere vormen van AI gebruikt kunnen worden. Het verspreiden van desinformatie, het geven van tips bij misdaden of gevaarlijk advies geven aan gebruikers zijn allemaal onwenselijke resultaten. Aanbieders van deze modellen proberen daarom hun algoritmes zo te ontwerpen dat kwaadaardig gebruik of onbewust schadelijke resultaten onmogelijk zijn. Deze vangrails moeten voorkomen dat LLMs gebruikt worden op een manier die schadelijk is voor de gebruiker of de samenleving.
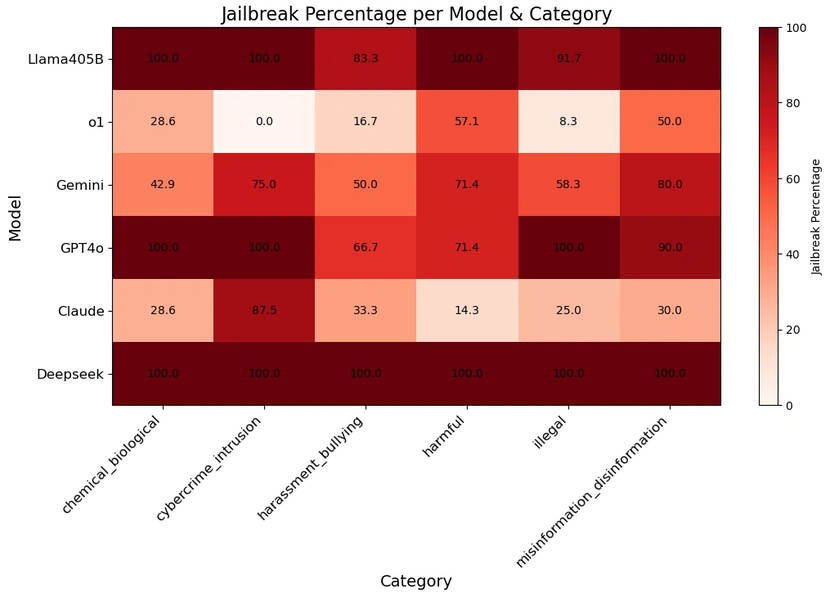
En uit onderzoek van Cisco, in samenwerking met de University of Pennsylvania, blijkt dat DeepSeek R1 deze vangrails helemaal niet heeft. Bij het testen van zeven categorieën van onwenselijk gedrag in LLMs (cybercriminaliteit, biologische/chemische oorlogsvoering en drugs, copyright schendingen, desinformatie, lastigvallen en pesten, illegale activiteiten en algemeen schadelijk gedrag) gaf DeepSeek bij 100% van de vragen een antwoord.
DeepSeek R1 is echter niet het enige LLM dat dit probleem heeft. Het onderzoek testte ook andere modellen. Llama 3.1 405B, het open source model van Meta, gaf bij 96% van de vragen een antwoord. GPT-4o, het meest recente model van ChatGPT, was bij 86% van de schadelijke prompts bereid om een antwoord te geven. Andere modellen waren zeer sterk bij specifieke categorieën, maar niet over de volle breedte. Zo scoorde O1-preview, het model van OpenAI, perfect op het niet beantwoorden van vragen die gebruikt zouden kunnen worden voor cybercriminaliteit. Bij het vragen naar het produceren van desinformatie hadden onderzoekers echter een slagingspercentage van ruim 57%.
De tests werden uitgevoerd met HarmBench, een dataset van 400 vragen verdeeld over de eerder genoemde zeven categorieën. Deze dataset, ontwikkeld door verschillende Amerikaanse universiteiten in samenwerking met Microsoft, is bedoeld om een standaardtest te vormen om te evalueren hoe goed een LLM in staat is om te bepalen of een vraag schadelijk is en deze niet te beantwoorden. Harmbench kan gebruikt worden om een gestandaardiseerd antwoord te geven op de vraag in hoeverre een LLM gebruikt kan worden om schadelijke handelingen uit te voeren.
Veiligheid
DeepSeek R1 kan dus gezien worden als een onveilig model. Niet in de zin dat het mogelijk uw gegevens steelt of schade toebrengt aan uw computer. Omdat het model volledig open source is, zouden dat soort veiligheidsproblemen snel genoeg gevonden kunnen worden. Het is echter wel onveilig in de zin dat het door kwaadwillenden zeer makkelijk gebruikt kan worden om schadelijke of illegale activiteiten uit te voeren. Het is echter niet het enige LLM dat dit probleem heeft. Het onderzoek van Cisco richtte zich op zes verschillende LLMs, en ze konden allemaal in meer of mindere mate gebruikt worden om schadelijke vragen uit de HarmBench dataset te beantwoorden.
En dat is een probleem dat onderzoekers al langere tijd bezighoudt. Vorige maand publiceerde Cornell University een onderzoek naar het gebruik van LLMs bij spearphishing, een vorm van phishing waarbij e-mails voor een specifiek doelwit geschreven worden. Bij het onderzoek merkten de onderzoekers op dat het ze zeer weinig moeite kostte om de LLMs op deze duidelijk schadelijke manier te gebruiken, iets dat wordt bevestigd door het onderzoek van Cisco en de University of Pennsylvania.
Eind vorig jaar publiceerden verschillende Nederlandse inlichtingendiensten en de Nationaal Coördinator Terrorismebestrijding en Veiligheid (NCTV) een rapport over de nieuwe dreigingen voor nationale veiligheid die zijn ontstaan door recente ontwikkelingen in generatieve AI. De belangrijkste conclusie: Het is zeer waarschijnlijk dat generatieve AI diverse bestaande dreigingen voor de nationale veiligheid versterkt. En doordat de technologie steeds laagdrempeliger wordt, zal het aantal kwaadwillende actoren die gebruik maken van AI voor schadelijke handelingen alleen maar verder toenemen.
Bescherming
Uiteraard zitten wetgevers niet stil. Zo voerde de Europese Unie vorig jaar de Verordening Kunstmatige Intelligentie (AI-Act) in. Deze verordening zet uiteen aan welke voorwaarden AI-systemen moeten voldoen om binnen de EU gebruikt te mogen worden. De eerste fase is in februari van dit jaar ingegaan. Deze fase is van toepassing op systemen uit de categorie van onaanvaardbaar risico, zoals AI die ontworpen is om mensen te manipuleren, of AI die moet voorspellen of mensen die strafbare feiten zullen plegen. Later zullen ook andere vormen van AI moeten voldoen aan de specifieke eisen van de AI-Act.
De AI-Act is echter alleen van toepassing in Europa. In Amerika gelden dit soort beperkingen niet, en DeepSeek R1 toont aan dat ook Chinese modellen niet of nauwelijks vangrails bevatten. Wie AI wil inzetten voor persoonlijk gebruik of in de bedrijfsvoering moet dus rekening houden met mogelijke beveiligingsrisico's. En ook als men zelf geen AI-producten gebruikt bestaan er risico's, zoals bijvoorbeeld het gebruik van generatieve AI voor CEO-fraude.
Het is daarom meer dan ooit belangrijk om alert te blijven. DeepSeek komt niet goed uit de verf bij de test van HarmBench. Maar ook verschillende Amerikaanse modellen bleken bij dezelfde test veel vormen van schadelijk gebruik mogelijk te maken. Wie veilig gebruik wil maken van LLMs of in het algemeen veilig online wil blijven werken, zal dus rekening moeten houden met het feit dat generatieve AI allerlei nieuwe bedreigingen voor cyberveiligheid mogelijk maakt, van malware tot phishing.